Wie man den besten Berater für ein Projekt findet
.jpg)
Wie man (Mitarbeiter-)Kompetenzen verwaltet
Wofür ein Beratungsunternehmen einen Wissensgraphen verwendet
Ein großes Unternehmen verfügt über Tausende von Dokumenten, Berichten und internen (unstrukturierten) Daten oder Wissen. Was ist, wenn all diese Daten zwar gespeichert sind, aber nicht genutzt werden können, weil es unmöglich ist, die benötigten Informationen zu sammeln? Stellen Sie sich ein Szenario vor, in dem es unerlässlich ist, Informationen schnell und präzise abzurufen, um einen Geschäftsvorteil zu erlangen. Zum Beispiel einen umfassenden Überblick über alle Mitarbeiter mit den gleichen Fähigkeiten oder darüber, wer wie lange an demselben Projekt gearbeitet hat?
Dies gilt eigentlich für jedes Unternehmen, das keine Produkte, sondern menschliche Fähigkeiten und Wissen verkauft, wie dies bei Beratungsunternehmen der Fall ist. Ein Szenario, in dem das Unternehmen von Natur aus auf Wissen zugreifen muss, um eine Geschäftsanfrage zu erfüllen, und eine schnelle Antwort ihm einen Vorteil gegenüber konkurrierenden Angeboten verschafft.
Schmerzpunkte
In dem obigen Beispiel - oder vielmehr in jedem Fall, in dem Informationen in einer großen Datenmenge verborgen bleiben - können Opportunitätskosten entstehen.
Um dem obigen Beispiel mehr Kontext zu verleihen:
- Stellen Sie sich einen neu eingestellten Mitarbeiter vor, dessen Erfahrungen und Fähigkeiten nicht im gesamten Unternehmen erfasst sind und der daher nicht für ein Projekt eingesetzt werden kann, für das er/sie am besten geeignet wäre.
- Denken Sie an verpasste Gelegenheiten zum Erfahrungsaustausch, zum Anbieten von Schulungen, zum Aufbau von Kompetenzen.
- Denken Sie an den hohen Zeitaufwand für die Pflege genauer Beraterprofile.
- Denken Sie an die Zeit, die Sie mit der Suche nach dem am besten geeigneten Mitarbeiter für eine Kundenanfrage verbringen und trotzdem nicht die passende Person finden. Oder im Suchprozess ausgebremst zu werden, weil die Verfügbarkeit der Kollegen nicht passt.
- Denken Sie an unzufriedene Mitarbeiter, die zu Projekten mit Technologien geschickt werden, an denen sie nicht mehr interessiert sind.
Unter diesen Umständen verlieren alle drei Beteiligten (Unternehmen, Kunde, Mitarbeiter), indem sie unzufrieden, ineffizient oder in vielerlei anderer Hinsicht ungewollt werden oder sind. Kurz gesagt: Jeder in der Gleichung zahlt Opportunitätskosten.
Eine Möglichkeit, sich diesem Szenario zu nähern und es zu vermeiden, kann ein Wissensgraph sein.
Die Lösung des Problems
Ein Wissensdiagramm kann die einzige Quelle der Wahrheit sein, um jedes Thema oder jede Informationsquelle zu erfassen. In unserem Beispiel: die Goldmine über die Fähigkeiten der Mitarbeiter.
Durch die Strukturierung von Mitarbeiterfähigkeiten, früheren Projekten, Zertifizierungen und sogar Soft Skills als ein miteinander verbundenes Netzwerk ermöglicht ein Knowledge Graph intelligente und präzise Mitarbeiterempfehlungen. Anstatt einfach nach vordefinierten Rollen zu filtern, versteht er, wie Fähigkeiten zusammenhängen, identifiziert verborgenes Fachwissen und schlägt Berater vor, die perfekt passen könnten - auch wenn sie keine exakte Stichwortübereinstimmung haben.
Was ist ein Knowledge Graph?
Ein Knowledge Graph ist eine strukturierte Art der Darstellung von Informationen als Netzwerk von Entitäten und deren Beziehungen. Im Gegensatz zu herkömmlichen Datenbanken, die Daten in Tabellen speichern, organisiert ein Knowledge Graph Informationen auf eine Weise, die reale Verbindungen widerspiegelt.
Die Gesamtstruktur setzt sich aus Knoten und Kanten zusammen. Knoten stellen Entitäten dar (z. B. Personen, Fähigkeiten, Projekte). Kanten definieren die Beziehungen zwischen ihnen (z. B. "John hat Python-Kenntnisse" oder "Maria arbeitete an Projekt X"). Durch die Erfassung von Kontext und Bedeutung ermöglicht ein Knowledge Graph intelligente Suche, Schlussfolgerungen und Empfehlungen.
Neo4j, eine Graphdatenbank, die speziell für die Verarbeitung stark vernetzter Daten entwickelt wurde
Neo4j ist eine native Graphdatenbank, d.h. sie ist für die effiziente Speicherung und Durchquerung von Graphstrukturen optimiert. Im Gegensatz zu relationalen Datenbanken, die mit komplexen Verknüpfungen zu kämpfen haben, ermöglicht Neo4j schnelle, intuitive Abfragen mit seiner Abfragesprache Cypher. Dies macht es zu einem leistungsstarken Werkzeug für Anwendungen wie den Abgleich von Mitarbeiterfähigkeiten, personalisierte Empfehlungen und datengesteuerte Entscheidungsfindung. Die verteilte Architektur gewährleistet eine nahtlose Skalierbarkeit, so dass Unternehmen jeder Größe - von kleinen Beratungsunternehmen bis hin zu globalen Konzernen - große Netzwerke von Mitarbeitern, Fähigkeiten und Projekten ohne Leistungseinbußen effizient verwalten und abfragen können.
Win-Win-Win
Ausgehend von den oben genannten Schmerzpunkten und der Darstellung eines Wissensgraphen wird deutlich, dass dieser Ansatz eine Win-Win-Win-Situation für alle Beteiligten darstellt.
- Das Unternehmen spart Zeit und Geld bei der Suche nach der besten Lösung für eine Kundenanfrage.
- Der Kunde erhält das Fachwissen, das er verlangt hat.
- Und der Mitarbeiter wird zu Projekten geschickt, für die er qualifiziert ist und die ihn interessieren.
Durch den Einsatz von Neo4j, einem Knowledge Graph zu jedem beliebigen Thema, kann ein Unternehmen ein dynamisches, skalierbares und intelligentes System aufbauen, mit dem es in kürzester Zeit auf die gewünschten Informationen zugreifen kann. In unserem Fall: Verwaltung von Fachwissen, Verbesserung der Personalauslastung und Bereitstellung eines hervorragenden Kundendienstes.
Was kommt als nächstes?
Im Anschluss daran werden wir uns damit beschäftigen, wie man einen Knowledge Graph mit Neo4j implementiert, um Informationen über die Mitarbeiter eines Beratungsunternehmens zu speichern und abzurufen. Dieses Beispiel wird zeigen, wie Fähigkeiten und Projekte mit Neo4j und Cypher verwaltet werden können und einen echten Geschäftsvorteil bieten.
Empfehlungssysteme vs. Suche vs. Filterung
Als Beratungsunternehmen ist es also unsere Aufgabe, den am besten geeigneten Mitarbeiter für ein Kundenprojekt zu finden. Ohne viele Details zu nennen, wissen wir, dass der Kunde jemanden braucht, der ein Projekt unterstützt, in dem Spring, Neo4j und MySQL zum Einsatz kommen. Glücklicherweise gibt es ein Tool, das uns helfen kann, den perfekten Berater für das Projekt zu finden. Werfen wir also einen Blick darauf, was man von einem solchen Tool erwarten kann.
Der Suchansatz
Nehmen wir zunächst an, dass wir alle möglichen Daten von den Beratern sammeln, die für dieses Beratungsunternehmen arbeiten. Zum Beispiel beschreiben alle Berater ihre Projekte, Fähigkeiten, Erfahrungen und Interessen an Technologien in unstrukturiertem Text. (Natürlich gefällt ihnen die Aufgabe, und alle Profile sind auf dem neuesten Stand.) Auf dieser Grundlage könnten wir also versuchen, unseren Kandidaten zu finden, indem wir in den Texten nach den gewünschten Technologien suchen. Aber haben alle die gleichen Begriffe verwendet? Was wäre, wenn jemand "Neo4j" schreibt, ein anderer nur "Graph Database" erwähnt und ein dritter den Namen der Cloud-Lösung "Aura" verwendet? Sie verstehen schon, wir werden nicht sicher sein, ob wir als Ergebnis alle möglichen Mitarbeiter bekommen, die für das von uns gewünschte Projekt geeignet sind.
Der Filterungsansatz
Stellen wir uns also einen stärker strukturierten Ansatz vor. Die Berater müssen ihre Fähigkeiten aus einer vordefinierten Ontologie auswählen. In der Folge können wir die Berater nach den angeforderten Fähigkeiten filtern und sollten alle Kombinationen von Fähigkeiten finden, die zu den Projektbedingungen passen. Perfekt, nicht wahr?
Was aber, wenn es keine perfekte Übereinstimmung gibt? Hier bietet sich ein iterativer Ansatz an: Einfach einen Filter entfernen, mehr Ergebnisse erhalten, und schon geht es los: von Hand suchen, ob die Personen in der Ergebnisliste unseren Anforderungen entsprechen. Der Aufwand wächst also mit jedem entfernten Filter und dem Aufspüren möglicher Ähnlichkeiten in bekannten Technologien.
Der Ansatz des Empfehlungssystems
Gehen wir noch einen Schritt weiter als die beschriebene Szenerie, in der wir von Hand suchen. Was wäre, wenn wir ein Graphenmodell verwenden, um die Fähigkeiten und Erfahrungen der Berater darzustellen. Die vordefinierte Ontologie der Fähigkeiten ist weiterhin gegeben, und wir strukturieren diese Begriffe in einem Graphen. So wird jede bestimmte Technologieerfahrung nun in einem Knoten enthalten sein. Wenn wir unsere Suche nach den gewünschten Fähigkeiten wieder aufnehmen, können wir nun einen anderen Ansatz verwenden:
Anstatt einfach zu prüfen, ob ein Berater über eine bestimmte Fähigkeit verfügt, berechnen wir die semantische Distanz zwischen dem, was gefragt wird, und dem, was jeder Berater tatsächlich kann.
Das Ergebnis? Wir geben nicht nur exakte Übereinstimmungen zurück. Stattdessen ordnen wir die Berater danach ein, wie gut ihr Qualifikationsprofil mit der Anfrage übereinstimmt, und platzieren die relevantesten Vorschläge an die Spitze.
Dahinter steckt ein einfacher, aber wirkungsvoller Gedanke: In vielen Fällen gibt es die perfekte Übereinstimmung nicht. Aber eine naheliegende und sinnvolle Alternative kann weitaus hilfreicher sein, als überhaupt nichts zu liefern. Schließlich sind Empfehlungen nicht nur für Streaming-Plattformen oder Einkaufswagen gedacht - sie können genauso nützlich sein, wenn es darum geht, Menschen mit dem richtigen Fachwissen zu verbinden.
Beispiel aus der Praxis
Das vorgestellte Beispiel ist zwar etwas vereinfacht, aber es handelt sich dennoch um ein Problem aus der realen Welt. Wir sind ein Beratungsunternehmen und haben einen Pool von Beratern mit unterschiedlichen Fähigkeiten und Erfahrungen an verschiedenen Standorten.
Warum ist es für uns so wichtig, mit wenig Aufwand die beste Übereinstimmung zu finden?
- Die Perspektive des Kunden
- Wenn ein Kunde um Unterstützung für ein bestimmtes Projekt bittet, erwartet er, dass ihm die besten Teammitglieder für dieses Projekt zur Verfügung gestellt werden.
- Die Perspektive des Arbeitnehmers
- Jeder Mitarbeiter möchte seine Stärken und Fähigkeiten einsetzen. Es wird frustrierend, an einem Projekt zu arbeiten, das nicht zu den eigenen Fähigkeiten und/oder Interessen passt. Frustrierte Mitarbeiter sind weniger motiviert und weniger produktiv. Es ist eine Situation, in der man nur verlieren kann.
- Die Perspektive des (Beratungs-)Unternehmens
- Das Unternehmen will den Kunden den besten Service bieten und die Mitarbeiter motiviert und zufrieden halten. Nur so kann der langfristige Erfolg gesichert werden.
Die Suche nach der besten Lösung kann also eine Win-Win-Win-Situation für den Kunden, das Unternehmen und den Mitarbeiter darstellen.
Hat der Berater Erfahrung mit einer bestimmten Technologie?
Es ist nicht an der Zeit, tiefer in das Graphenmodell einzutauchen. Um das genannte Beispiel zu verfeinern: Ein Berater kann auf verschiedene Weise Fachwissen über Technologien erworben haben.
- Verwendung einer Fähigkeit: Der offensichtliche Weg ist, dass ein Berater Erfahrung mit einer Technologie hat, weil er sie in einem Projekt eingesetzt hat.
- Zertifizierung: Eine andere Möglichkeit ist, dass ein Berater eine Zertifizierung für eine Technologie besitzt. Das bedeutet nicht, dass er sie in einem Projekt eingesetzt hat, aber er verfügt über Kenntnisse.
- Interesse: Ein Berater kann auch ein Interesse an einer Technologie haben. Dies bedeutet, dass er/sie Zeit damit verbracht hat, diese Technologie zu erlernen/anzuwenden, aber keinen Nachweis in Form eines Zertifikats oder der Mitarbeit an einem Projekt mit dieser Fähigkeit hat.
- Ähnliche Qualifikationen: Vielleicht ist der Mitarbeiter ein Experte für eine ähnliche Technologie. Wenn zum Beispiel jemand Erfahrung mit MySQL hat, ist es wahrscheinlich, dass er auch mit Postgres arbeiten kann.
Beginnen wir mit dem Graphenmodell unter Verwendung von Cypher-Anweisungen, um die verschiedenen Pfade zwischen der Person und den angeforderten Fähigkeiten zu sehen.
Das Diagramm-Modell
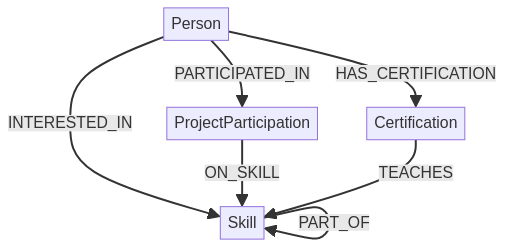
Wie die Suche nach der besten Übereinstimmung funktioniert
Definieren Sie zunächst ein Punktesystem. Die Festlegung eines Bewertungssystems ist entscheidend für den Erfolg des Empfehlungssystems, um die Ergebnisse nach Punkten zu ordnen (was wir ja wollen!). Ob ein Interesse höher bewertet wird als eine Zertifizierung, ist eine geschäftliche Entscheidung, kann aber einen großen Einfluss auf die Akzeptanz des Empfehlungssystems haben.
Lassen Sie uns drei Berater definieren, die wir vergleichen wollen.
- Beraterin Alice:
- Java: 2 Jahre Erfahrung und zertifiziert
- Neo4j: 3 Jahre Erfahrung
- Postgres: 1 Jahr Erfahrung
- Berater Bob:
- Java: 15 Jahre Erfahrung
- Neo4j: nichts
- MySQL: 2 Jahre Erfahrung
- Mallory:
- Java: nichts
- Neo4j: nichts
- MySQL: 1 Jahr Erfahrung
Wir suchen einen Berater mit Erfahrung in Java, Neo4j und MySql. Welches Ergebnis würden Sie erwarten? 1. Alice, weil sie direkte Erfahrung mit Java und Neo4j hat und Postgres ähnlich wie MySQL ist. 2. Bob, weil er die meiste Erfahrung mit Java und MySQL hat 3. Mallory, weil er nur Erfahrung mit MySQL hat
Wir müssen also ein Punktesystem festlegen, das unsere Erwartungen widerspiegelt. - Erfahrung: 1 Punkt pro Monat der Erfahrung - Zertifizierung: 10 Punkte - Interesse: 5 Punkte
Ähnliche Fähigkeiten sind etwas komplexer. Erinnern Sie sich, dass eine grafische Darstellung die Möglichkeit bietet, den Abstand zwischen den angeforderten Fähigkeiten und den Fähigkeiten der Personen zu berechnen? Dies kommt ins Spiel, wenn wir herausfinden wollen, wer ähnliche Erfahrungen für eine angefragte Technologie hat.
Wenn wir einen Berater mit Erfahrung in Postgres haben, ist es wahrscheinlich, dass er/sie auch mit MySQL arbeiten kann, da beide eine Art relationale Datenbank sind. Wir können also den Abstand zwischen MySQL (angefragt) und Postgres (nahe an MySQL und gegeben) berechnen. Wir berechnen den kürzesten Weg zwischen der angefragten Fähigkeit und der am nächsten liegenden Fähigkeit, d.h. dieses Beispiel zeigt die Entfernung von Neo4j und Postgres zu MySQL.
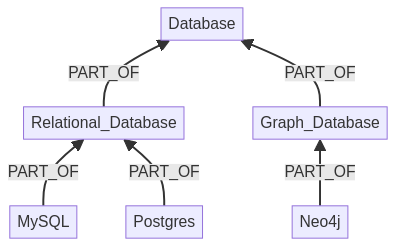
Der Abstand von Neo4j zu MySQL ist also 4 und von Postgres zu MySQL ist 2. Wir können also unsere vordefinierten Werte durch den Abstand teilen.
Normalisierung
Die Noten sind nicht direkt vergleichbar. Denn 15 Jahre Erfahrung führen zu einer so hohen Punktzahl, dass die anderen Punktzahlen nicht mehr relevant wären. Wir müssen also die Werte normalisieren, und das geht am einfachsten, indem wir die Punktzahl durch die Höchstpunktzahl teilen.
Dies kann aber immer noch einen großen Einfluss auf die Punktzahl haben und das Ergebnis verzerren. Ein anderer Ausweg ist die Verwendung des Logarithmus der Punktzahl, wodurch der Einfluss des Erfahrungswerts verringert wird.
Im nächsten Kapitel werden weitere Einzelheiten der Berechnung beschrieben.
Die Kalkulation
Wir suchen nach einem Berater mit Erfahrung in Java, Neo4j und Postgres.
Erstellen einer Punktzahl für jede geforderte Fähigkeit
- Beraterin Alice:
- Java: 2 Jahre Erfahrung und zertifiziert
- Neo4j: 3 Jahre Erfahrung
- Postgres: 1 Jahr Erfahrung
- Berater Bob:
- Java: 15 Jahre Erfahrung
- Neo4j: nichts
- MySQL: 2 Jahre Erfahrung
- Mallory:
- Java: nichts
- Neo4j: nichts
- MySQL: 1 Jahr Erfahrung
Java - Alice: 2 Jahre Erfahrung in Java und eine Zertifizierung - (2 * 12) + 10 = 34 - Bob: 15 Jahre Erfahrung in Java - 15 * 12 = 180 - Mallory - = 0 - Normalisierte Punktzahl - Alice: 34 - Bob: 180 - Mallory: 0
Neo4j - Alice: 3 Jahre Erfahrung mit Neo4j und Interesse - 3 * 12 + 5 = 41 - Bob: 0 - Mallory: 0
Postgres - Alice: 1 Jahr Erfahrung mit Postgres - Entfernung zu Postgres: 2, Entfernung zu Neo4j: 4 wir addieren eins, weil wir nicht durch 0 teilen wollen - (12 / 3) + (5 / 5) = 5 - Bob: 2 Jahre Erfahrung mit MySQL - 24 = 24 - Mallory: 1 Jahr Erfahrung mit MySQL - 12 = 12
Normalisierte Punktzahl
- Alice: 34 + 41 + 6 = 81
- Bob: 180 + 0 + 24 = 204
- Mallory: 0 + 0 + 12 = 12
Die Gesamtpunktzahl für Alice ist also 2,19 und für Bob 2.
Alice ist also der beste Kandidat für die geforderten Fähigkeiten. Wenn Alice jedoch nicht verfügbar ist, ist Bob die zweitbeste Übereinstimmung und in unserem Fall ist er bereit, Neo4j zu lernen, um coole Empfehlungssysteme zu bauen.
Implementierung in Neo4j
Zunächst müssen wir unser Graphenmodell definieren.
Überprüfen wir unsere Annahmen.
Prüfen Sie nun die Zertifizierungen.
Nun zu den Interessen.
Ok, wenn alles korrekt ist, können wir die Punkte berechnen. Beginnen wir mit dem Zinsergebnis.
Sie sehen, dass wir für Alice auch einen Interessenwert für MySQL erwarten, weil sie sich für eine andere Datenbank interessiert. Nun der Zertifizierungswert.
Jetzt die Erlebnisbewertung. Hier wird es etwas komplexer, denn wir müssen die Dauer des Erlebnisses berechnen.
Sie können sehen, dass Bob und Mallory auch einige Punkte für Neo4j erhalten, da sie Erfahrung mit einer Datenbank haben. Zunächst fassen wir alles in einer Anweisung zusammen.
Nun können wir die Werte normalisieren. Zur besseren Lesbarkeit beginnen wir mit dem Rückgabeteil
Nun die Schlusserklärung
Nun konnten wir mit nur einer Abfrage ein Empfehlungssystem in Neo4j implementieren.
.jpg)
Weitere verwandte Themen

Warum eine starke Produkt-Roadmap der Schlüssel zur erfolgreichen Softwareentwicklung ist
Was macht eine Produkt-Roadmap gut und wertvoll? Wie können Sie sie effektiv erstellen und pflegen? Wir untersuchen, warum sie wichtig ist und welche Vorteile sie bringt. Lesen Sie und entdecken Sie die besten Methoden, um eine Roadmap zu erstellen und lebendig zu halten.
Mehr lesen
12 ChatGPT-Anwendungsfälle für Unternehmen
Künstliche Intelligenz (KI) hat sich zu einer der beliebtesten und am schnellsten voranschreitenden Technologien entwickelt. Die neuesten OpenAI-Modelle haben die Effizienz und Automatisierung verschiedener Aufgaben erheblich verbessert. Unter diesen Modellen hat sich ChatGPT als das führende generative KI-Modell herauskristallisiert, das das Internet im Sturm erobert.
Mehr lesen
Wie man GitHub Copilot verwendet: Ein KI-Codierungsassistent (Demo)
In diesem Artikel führen wir Sie durch die Funktionen und Vorteile von GitHub Copilot, einem innovativen KI-gestützten Coding-Assistenten, indem wir eine Coding-Demo zeigen. Als Nutzer von GitHub Enterprise und GitHub Advanced Security haben wir aus erster Hand Erfahrungen mit diesem KI-Codierassistenten gesammelt, was uns dazu veranlasst hat, unsere Erkenntnisse und unser Fachwissen zu teilen.
Mehr lesen