How to Find the Best Consultant for a Project
.jpg)
How to manage (employee) skills
What a consultant company uses a knowledge graph for
A large organisation has thousands of documents, reports & internal (unstructured) data or knowledge. What if all that data is stored but cannot be used, due to the fact that it is impossible to gather the specific information needed? Imagine a scenario where it is essential to retrieve information quickly and precisely in order to gain a business advantage? For example, an comprehensive overview of all employees sharing the same skills or who has worked in the same project for what amount of time?
This actually is the case for any company that does not sell products but human skills and knowledge like consultant companies do. A scenario where the company inherently needs to access knowledge to fulfill a business request and a quick response gives it an advantage over competing offers.
Pain points
Given the example above - or rather any case where information stays hidden within the large amount of data - opportunity costs (could) arise.
To add more context to the example above:
- Think of a newly hired employee whose experience and skills are not captured within the whole company and thus cannot be sent to a project that he/she would be best suitable.
- Think of missed opportunities in sharing experiences, offering training courses, building skills.
- Think of the large amount of time spent to maintain accurate consultant profiles.
- Think of the time spent searching for the best fit of an employee for a customer request and still missing the matching person. Or being thwarted in the search process because the availability of colleagues is not suitable.
- Think of unhappy employees who are sent to projects with technologies they are not interested in anymore.
This given, all three participants (company, customer, employee) lose by becoming or being unhappy, unefficient or many more undesired things. To put it short: everyone in the equation pays opportunity costs.
A way to approach and avoid this scenario can be a knowledge graph.
Solving the problem
A knowledge graph can be the single source of truth for capturing any topic or source of information. In our example: the gold mine about employee skills.
By structuring employee skills, past projects, certifications, and even soft skills as an interconnected network, a Knowledge Graph enables intelligent and precise employee recommendations. Instead of simply filtering by predefined roles, it understands how skills relate, identifying hidden expertise and suggesting consultants who may be a perfect fit—even if they don’t have an exact keyword match.
What is a Knowledge Graph?
A Knowledge Graph is a structured way of representing information as a network of entities and their relationships. Unlike traditional databases that store data in tables, a Knowledge Graph organizes information in a way that mirrors real-world connections.
The overall structure is made of nodes and edges. Nodes represent entities (e.g., people, skills, projects). Edges define relationships between them (e.g., "John has Python expertise" or "Maria worked on Project X"). By capturing context and meaning, a Knowledge Graph enables intelligent search, reasoning, and recommendations.
Neo4j, a graph database designed specifically for handling highly connected data
Neo4j is a native graph database, meaning it is optimized to store and traverse graph structures efficiently. Unlike relational databases, which struggle with complex joins, Neo4j allows for fast, intuitive queries using its Cypher query language. This makes it a powerful tool for applications such as employee skill matching, personalized recommendations, and data-driven decision-making. Its distributed architecture ensures seamless scalability, allowing companies of any size—from small consultancies to global enterprises—to efficiently manage and query vast networks of employees, skills, and projects without performance degradation.
Win-Win-Win
Based on the pain points from above and the illustration of what a knowledge graph is, it becomes obvious that this approach is a win-win-win situation for everyone involved.
- The company saves time and money finding the best fit regarding a customer request.
- The customer gets the expertise they asked for.
- And the employee gets sent to projects that they are skilled for and interested in.
By leveraging Neo4j, a Knowledge Graph about any topic of interest a company can build a dynamic, scalable, and intelligent system for accessing the desired information in no time. In our case: managing expertise, improving workforce utilization, and delivering superior client service.
What comes next?
As a follow up we will deep dive on how to implement a Knowledge Graph using Neo4j to store and access information about employees of a consultant company. This example will demonstrate how skills and projects can be managed and provide a real business advantage using Neo4j and Cypher.
Recommendation systems vs Search vs Filtering
So, as a consulting company our task is to find the best fit of an employee for a customer project. Without much detail we know that the customer need refers to someone to support a project where Spring, Neo4j and MySQL are used. Luckily, there is a tool that can help us find the perfect match of a consultant for the project. So, let’s have a look on what to expect from such tool.
The Search approach
First of all, let’s assume we collect all the data possible from the consultants working for that consultant company. For example, all consultants describe their projects, skills, experience and interests in technologies in unstructured text. (Of course they like the task and everyone’s profile is up to date.) So, from that we could try searching for our candidate by searching for the desired technologies in the text. But did everyone use the same terms? What if someone wrote “Neo4j”, someone else mentions just “Graph Database” and a third person used the name from the Cloud Solution “Aura”? You get it, we won’t be sure, if we’d get all possible employees as a result, suitable for the project we’d like.
The Filtering approach
So, let’s picture a more structured approach. The consultants have to select their skills from a predefined ontology. As a consequence, we then can filter the consultants by the requested skills and should find all person skill combinations suiting the project conditions. Perfect, isn’t it?
But what if there is no perfect match? An iterative approach is the obvious choice: Simply, remove one filter, get more results, and you get it: search by hand whether the people in the result list fit our needs. So the effort grows with each filter removed and tracing possible similarities in technologies known.
The Recommendation System approach
Let’s move on and go a step further the described scenery in which we search by hand. What if we use a graph model to represent the skills and experiences of the consultants. The predefined ontology of skills still given, and structure those terms in a graph. Thus each certain technology experience will now be contained in a node. Revisiting our search for the requested skills, we now can use a different approach:
Instead of simply checking whether a consultant has a specific skill, we calculate the semantic distance between what’s being asked for and what each consultant actually has experience in.
The result? We don’t just return exact matches. Instead, we rank the consultants by how closely their skill profiles align with the request — placing the most relevant suggestions at the top.
Underlying this is a simple but powerful idea: in many cases, the perfect match doesn’t exist. But a close and meaningful alternative can be far more helpful than returning nothing at all. After all, recommendations aren’t just for streaming platforms or shopping carts — they can be just as useful when connecting people with the right expertise.
Real-world example
The example presented is a bit simplified, but still it was a real-world problem. We are a consulting company, and we have a pool of consultants with different skills and experiences in different locations.
So why is it important for us to find the best match with little effort?
- The Customer’s Perspective
- When a customer asks for support on a specific project, they expect to be provided the best team members for the project.
- The Employee’s Perspective
- Each employee wants to use their strengths and skills. It becomes frustrating to work on a project that doesn’t fit their skills and/or interests. Frustrated employees are less motivated and less productive. It’s a lose-lose situation.
- The (Consultant) Company’s Perspective
- The company wants to provide the best service to the customer and keep the employees motivated and satisfied. This is the only way to ensure long-term success.
So, finding the best fit can be a win-win-win situation for the customer, the company, and the employee.
Does a consultant have experience with a technology?
Not it’s time to dive deeper into the graph model. Refining the example given, a consultant can have gained expertise in technologies from several ways.
- Using a Skill: The obvious way is that a consultant has experience with a technology because he used it in a project.
- Certification: Another way is that a consultant has a certification for a technology. This doesn’t mean he has used it in a project, but he has knowledge.
- Interest: A consultant can also have an interest in a technology. This means, he/she has spent time learning/using that technology but has no proof by owning a certificate or time on a project with that skill.
- Similar Skills: Perhaps the employee is an expert in a similar technology. For example, if someone has experience with MySQL, it is likely that there are abilities to also work with Postgres.
Let’s start with the graph model using Cypher statements to see the different paths between the person and the requested skills.
The Graph Model
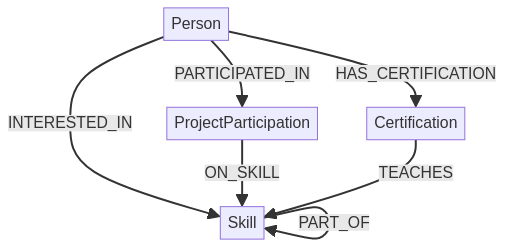
How the search for the best match works
First, define a scoring system. Defining a scoring system is crucial for the success of the recommendation system, in order to order the results by score (which we want!). Whether to score an interest higher than a certification, is a business decision, but can have a big impact on the acceptance of the recommendation system.
Let’s define three Consultants that we want to compare.
- Consultant Alice:
- Java: 2 years of experience and certified
- Neo4j: 3 years of experience
- Postgres: 1 year of experience
- Consultant Bob:
- Java: 15 years of experience
- Neo4j: nothing
- MySQL: 2 years of experience
- Mallory:
- Java: nothing
- Neo4j: nothing
- MySQL: 1 years of experience
We search for a consultant with experience in Java, Neo4j, and MySql. What result would you expect? 1. Alice, because she has direct experience in Java and Neo4j and Postgres is similar to MySQL. 2. Bob, because he has the most experience in Java and MySQL 3. Mallory, because he has only experience in MySQL
So we need to define a scoring system that reflects our expectations. - Experience: 1 points per month of experience - Certification: 10 points - Interest: 5 points
Similar skills are somewhat more complex. Remember that a graph representation offers the possibility to calculate the distance between requested skills and skills of the people? This comes into play when we want to find out who has similar experience for a requested technology.
If we have a consultant with experience in Postgres, it is likely that he/she can also work with MySQL because both are a kind of Relational Database. So we can calculate the distance between MySQL (requested) and Postgres (close to MySQL and given). We calculate the shortest path between requested skill and closest matching skill, i.e. this example shows the distance from Neo4j and Postgres to MySQL.
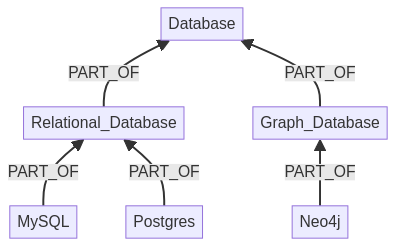
So the distance from Neo4j to MySQL is 4 and from Postgres to MySQL is 2. So we can divide our predefined scores by the distance.
Normalization
The scores are not directly comparable. Because 15 years of experience will result in such a high score that the other scores would not be relevant anymore. So we need to normalize the scores and the simplest way to do so is by dividing the score by the maximum score.
But this can still have a huge impact on the score and can distort the result. Another way out is to use the logarithm of the score, which will reduce the impact of the experience score.
The next chapter will describe more details about the calculation.
The Calculation
Let’s search for a consultant with experience in Java, Neo4j, and Postgres.
Creating a Score for each requested skill
- Consultant Alice:
- Java: 2 years of experience and certified
- Neo4j: 3 years of experience
- Postgres: 1 year of experience
- Consultant Bob:
- Java: 15 years of experience
- Neo4j: nothing
- MySQL: 2 years of experience
- Mallory:
- Java: nothing
- Neo4j: nothing
- MySQL: 1 years of experience
Java - Alice: 2 years of experience in Java and a certification - (2 * 12) + 10 = 34 - Bob: 15 years of experience in Java - 15 * 12 = 180 - Mallory - = 0 - Normalized Score - Alice: 34 - Bob: 180 - Mallory: 0
Neo4j - Alice: 3 years of experience in Neo4j and interested - 3 * 12 + 5 = 41 - Bob: 0 - Mallory: 0
Postgres - Alice: 1 year of experience in Postgres - Distance to Postgres: 2, Distance to Neo4j: 4 we add one, because we don’t want to divide by 0 - (12 / 3) + (5 / 5) = 5 - Bob: 2 years of experience in MySQL - 24 = 24 - Mallory: 1 year of experience in MySQL - 12 = 12
Normalized Score
- Alice: 34 + 41 + 6 = 81
- Bob: 180 + 0 + 24 = 204
- Mallory: 0 + 0 + 12 = 12
So the total score for Alice is 2.19 and for Bob 2.
So Alice is the best match for the requested skills. But if Alice is not available, Bob is the second-best match and in our case he is willing to learn Neo4j to build cool recommendation systems.
Implementation in Neo4j
First, we need to define our graph model.
Let’s check our assumptions.
Now check the certifications.
Now the interests.
Ok, if everything is correct, we can calculate the scores. Let’s start with the interest score.
You see that we also expect an interest score for Alice in MySQL, because she is interested in another database. Now the certification score.
Now the experience score. Here it would be a little bit more complex, because we need to calculate the duration of the experience.
You can see that Bob and Mallory also receive some score points for Neo4j, because they have experience with a database. First, we combine everything in one statement.
Now we can normalize the scores. For readability, we start from the return part
Now the final statement
Now we were able to implement a recommendation system in Neo4j with only one query.
.jpg)
More related topics

Why a Strong Product Roadmap is Key to Successful Software Development
What makes a product roadmap good and valuable? How can you create and maintain it effectively? We explore why it is important and what benefits it drives. Read and discover the best practices for creating and keeping a roadmap vivid and alive.
Read More
12 ChatGPT Use Cases for Businesses
Artificial Intelligence (AI) has become one of the most popular and rapidly advancing technologies. The latest OpenAI models have significantly improved efficiency and automation in various tasks. Among these models, ChatGPT has emerged as the leading generative AI model taking the internet by storm.
Read More
How to Use GitHub Copilot: An AI Coding Assistant (Demo)
In this article, we will guide you through the features and advantages of GitHub Copilot, an innovative AI-powered coding assistant, by showcasing a coding demo. As users of GitHub Enterprise and GitHub Advanced Security, we have firsthand experience utilizing this AI coding assistant, which has prompted us to share our insights and expertise.
Read More